MySQL知识系列二:MySQL索引
存储引擎与底层实现的数据结构
数据结构 - 索引怎么选择合适的数据结构?中分析过能作为索引的数据结构主要有散列表(Hash表)、红黑树、跳表、B+树(B树)以及有序数组,并且分析了它们适合场景。Mysql的索引与存储引擎相关,但是Mysql内常用的存储引擎有InnoDB、MyiSAM、Memory,在Mysql5.5版本后,InnoDB已经作为默认的存储引擎,并且很多互联网公司基本都要求只能使用InnoDB存储引擎。Memory作为临时表的默认存储引擎,所以研究的重点基本就是InnodDB和Memory引擎,也就是基本关注B+树和散列表的数据结构索引。他们底层支持的数据结构如下图:
| MyISAM | InnoDB | Memory | |
|---|---|---|---|
| B+Tree索引 | √ | √ | √ |
| Hash索引 | √ | ||
| R-Tree索引 | √ | ||
| Full-text索引 | √ |
InnoDB存储引擎本身只支持B+树,之前分析过B+树比较适合磁盘存储。B+树是多路平衡搜索树,最佳实践N值为1200左右,树高为4时就可存储 1200的3次方,此时已经存储了17亿数据了。由于第一层数据总是在内存中,那么相当于17亿数据,最多查询磁盘3次,如果第二层刚好也在内存中,那么对多查询2次磁盘。也就是说InnoDB的最底层数据结构是B+树,B+树可能存储在内存中可能存储在磁盘中,存储的单元是数据页(操作系统数据缓存页),即数据缓存页是内存和磁盘的链接点。磁盘 -> 数据页 -> 内存
而查询数据所在的行到达在内存中还是在磁盘中,由服务器所在的 InnoDB缓存页大小决定,Buffer Pool由 my.cnf配置中的参数控制:
innodb_buffer_pool_size:引擎的缓存池大小,一般为物理内存的60% - 80%;innodb_buffer_pool_instances:IBP(InnoDB Buffer Pool)的个数,Linux系统,如果innodb_buffer_pool_size大小超过1GB,innodb_buffer_pool_instances值就默认为 8;否则,默认为 1;
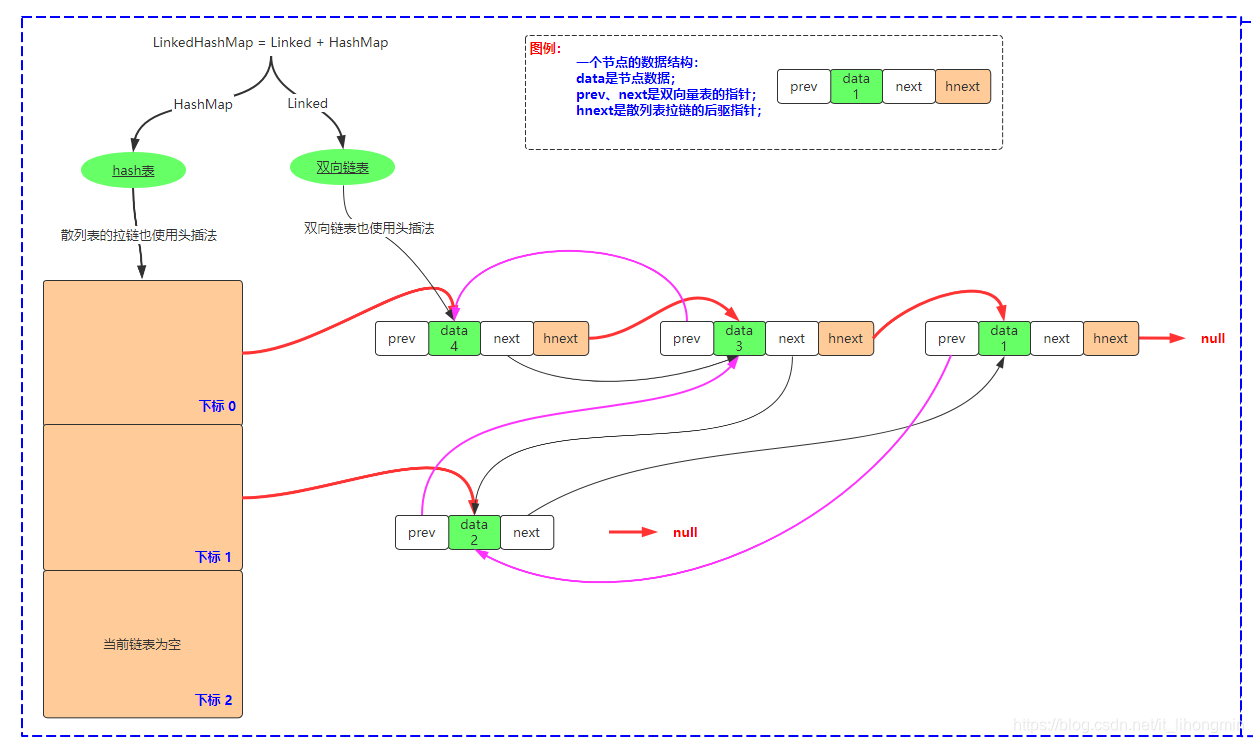
缓存的大小有限,那么只能将数据命中率最高的放入缓存中,Mysql使用的LRU缓存淘汰算法。LRU可以理解成一个链表,链表的节点就是数据缓存页,刚被访问过的放到链表一头,最老被访问过的放到一头,当有新的数据缓存页被访问加入时,从最老的一头淘汰。但是链表本身删除节点的时间复杂度是O(1),但是访问时间复杂度是O(N),性能很低。怎么才能提高访问性能呢? 一般会使用散列表进行访问,即整个LRU由散列表+双向链表组成,类似于Java中的LinkedHashMap的数据结构。
由于磁盘局部性原理,访问数据页时有预读数据页的功能,即我们从磁盘中获取到了多余的数据页,加入LRU的话就是浪费存储空间。还有我们可能会(处理报表等sql)对一个历史数据表进行整表分页全表查询一遍,那么也会对LRU照成冲击,可能需要很长的时间才能让缓存命中率恢复。针对预读数据页和冷数据扫描的情况,Mysql对LRU进行了改造,将LRU链分成 5/8的young区和 3/8的old区。当数据需要淘汰时直接从old区的末尾开始,而当新访问数据页时先判断在缓存中是否存在,如果不存在则直接将数据添加到old区,否则当满足下面配置时才会真正移动到young区域:innodb_old_blocks_time:mysql缓存页使用的LRU,old区升级为young区的时间判断。默认值1000,单位毫秒;